Running Kubernetes Workload on Amazon EC2 Spot Instances
Spot Instances provide up to 90% of the cost savings but dealing with them is like playing with fire. With an advance Kubernetes configuration, you can automate the workload transfer and mitigate the risk of interruptions.
Amazon defines a Spot Instance as ‘an unused EC2 instance that’s available for less than the On-Demand price.'
I call them significantly cheaper instances that AWS snatches away from you when it can get more money for them.
For example, when someone requests an On-Demand Instance or a Reserved Instance, and capacity is close to at-limit, AWS will terminate your Spot Instance to free up capacity for them.
An upcoming Spot Instance interruption only has a 2-minute advance notice. Yes, 2 minutes.
A 2-minute window might seem too tight at first glance, but when you’re working with automated configurations, it’s more than enough, as you’ll see below.
Does the 2-minute advance notice make Spot Instances useless? Certainly not. But it does mean you have to be careful when you decide to leverage them.
When should You Use Spot Instances?⌗
Due to the inherent risk of an instance getting reclaimed (interrupted), I’ve seen businesses ignoring the tremendous cost savings on offer. To be clear, I’m not saying you should increase your risk to grab those savings at all.
No. That’s a bad idea.
But the savings are too substantial to ignore. They really are! Thankfully, there’s a way to enjoy those savings without compromising on stability.
Even if we ignore the fact that AWS continuously releases data about the spot instance interruptions (averaged <10%) via a tool called Spot Instance Advisor, we should still match workloads that can handle these interruptions just fine. Containerized workloads are often stateless and fault-tolerant, making them a perfect fit for Spot Instances. There are many such examples.
Jenkins CI/CD pipelines can also leverage the cost savings of Spot Instances. Lyft made headlines when they reported 90% savings by using Spot Instances for their Jenkins pipeline back in 2016!
But I digress—more on that in another post. Let’s get back to Spot Instances and Containers now!
What Sorts of Cost Savings Can You Expect?⌗
The cost savings you can enjoy can range from a respectable 50% to a whopping 90%. Remember, I told you that the savings are just too substantial to ignore?
In fact, you can save even more if you diversify your instances across multiple AZs (Availability Zones) to ensure you can grab any available capacity at relatively lower prices.
Yes, you do have to invest time and resources to deploy containers on Spot Instances without affecting resilience in the slightest. But the savings will soon make that investment more than worth it.
Interruptions and Risk Management: Don’t Blindly Trade Lower Costs for Increased Risk!⌗
From what I’ve noticed, older generation instances have fewer interruptions (as reported by AWS). Yes, you can handle any interruptions, but it’s still good practice to avoid them as much as possible. Here is a list of Spot Instances from AWS with their configurations, frequency of interruption, and savings over On-Demand.
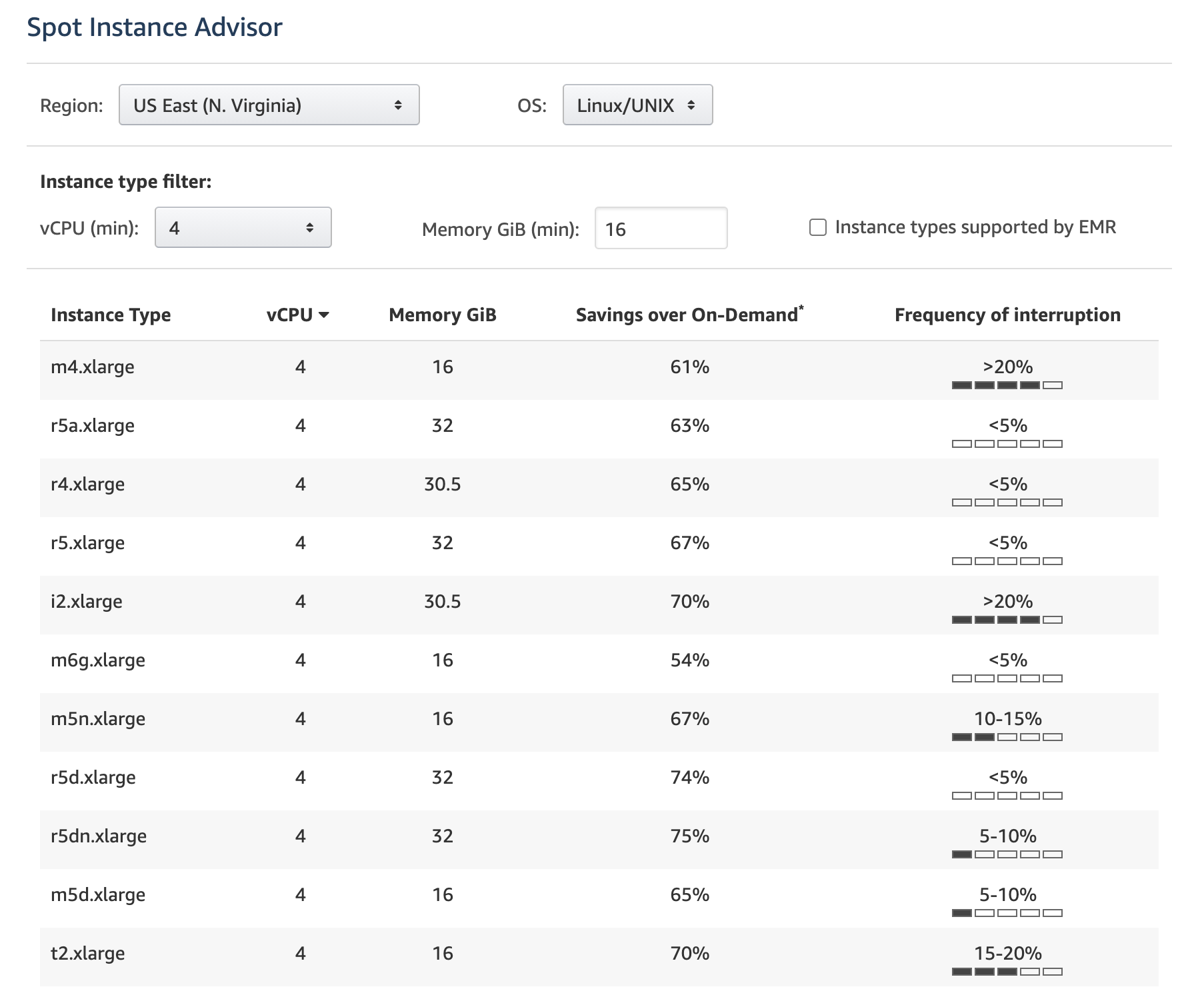
Source - AWS Spot Instance Advisor (September 2020)
Thanks to the way containerized workloads are designed, risk mitigation to account for interruptions is relatively straightforward.
That said, do make sure you know what you’re doing to avoid courting disaster. Be careful!
Node Termination Handler and Auto Scaling Groups⌗
Now, EC2 will send you spot instance interruption notices as and when it needs that compute power back. It’s up to you to handle this termination gracefully, without any business interruption.
That’s where the AWS Node Termination Handler comes in handy.
You do need to handle a terminating instance. But that’s just the interruption aspect of working with Spot Instances. Suppose AWS did stop a Spot Instance, and you managed to ensure that your pod terminated gracefully. Now, after the termination, what if you don’t have the required compute capacity to meet your application’s demand?
That’s precisely why there are two aspects to mitigating the risk of working with Spot Instances when working with Kubernetes:
- Exit Gracefully (Interruption): Ensure that your running pods exit gracefully from a terminating node as soon as you detect an interruption notice.
- Maintain Compute (Resumption): Make sure that even if AWS terminates some of your Spot Instances, you scale to the required compute power, so your application’s demands are still met. Auto Scaling is one of the most common ways of doing this.
Missing out on one can threaten your business continuity, so pay attention when working with Spot Instances. The savings are attractive enough to warrant the time and resources you’ll spend setting this up initially.
While the interruption workflow deals with safely terminating a pod, the resumption workflow ensures that your overall compute remains unchanged – regardless of AWS reclaiming any number of Spot Instances from that pool.
Here’s an ideal workflow for correctly handling a 2-minute interruption notice without disrupting your application:
Interruption Workflow
- IDENTIFY: Detect a Spot Instance interruption notice as soon as possible and identify the affected node.
- PREPARE: The two-minute window has started; prepare the node for a graceful termination.
- TAINT: Not only do you need to terminate a running pod, but you also must take care that no new pods are placed into a soon-terminating node. Tainting the node essentially cordons it off, preventing new pods from being placed on it.
- DRAIN: The last step that evicts running pods from your terminating Spot Instance is draining from load balancers. Giving pods a chance to terminate gracefully is much better than an abrupt KILL signal. Resumption Workflow
- REPLICATE: Controllers like ReplicaSet will notice a missing pod and create a new replica to replace it.
- AUTO SCALERS: They scale capacity as required for the generated replica, provisioning new instances as configured.
Autoscaling Kubernetes Clusters with Spot Fleets⌗
When you’re configuring your Auto Scaler, AWS offers a fair bit of flexibility to account for varied application requirements. You can pick from what sort of scaling would best suit your Kubernetes workloads with a quick assessment.
Spot Fleets are pretty much what they sound like.
They’re fleets (collections) of Spot Instances, and optionally, On-Demand Instances that launch and terminate to match your configuration.
There are 4 types of allocation strategies to scale your fleet as required:
- lowestPrice: As the name indicates, this strategy simply picks from the pool with the lowest price at the time of allocation. By default, AWS will use lowestPrice as your strategy.
- diversified: Spot Instances launched will be distributed across all instance pools.
- capacityOptimized: Some types of pools will offer lower interruption rates, and this allocation strategy accounts for real-time capacity data and launches into pools with the most availability. The capacityOptimized strategy comes in handy when interrupting an instance leads to higher costs (and/or opportunity costs) for certain workloads.
- InstancePoolsToUseCount: The Spot Instances are spread across your chosen pools. However, this strategy requires the combined use of the lowestPrice for it to be a valid configuration.
As I’ve detailed above, keeping your Kubernetes workload afloat on interrupting instances isn’t rocket science. You cut a massive chunk of your cloud costs by switching over from On-Demand instances to Spot Instances for containers – without affecting your application’s reliability in the least.
Deploy a fleet across several types of instances, sizes, and even AZs (Availability Zones/Regions) for the most effective (cost-wise and stability-wise) scaling of your cluster. You can also improve reliability by including On-Demand instances in your fleet.
A quick warning here. Don’t go overboard trying to cut down on your AWS bill by compromising on stability. Make sure you configure fail-safes like On-Demand instances within your Spot Fleets to ensure that your workload isn’t left hanging.
PS. If you’re unsure whether you can make use of these crazy savings by switching to Spot Instances, reach out to us, and I’ll be glad to have a chat with you! Head over to Egen and schedule a free 30-minute consultation with me.